
Research log #1
Small Data, Big Model - Is this model design an overkill?
By Lidia on Fri Jun 06 2025
Context
We’re building a solution for tabular data deduplication and entity matching.- Require data to be paired in advance
- Depend heavily on labeled training data
- Rely on surface-level string similarity (Levenshtein, Jaccard, etc.)
Can we leverage deep learning to generate entity-level embeddings for entity matching?
💡 Today’s Key Question
Given that we only have ~4,000 rows and many missing values, is this model design overkill?
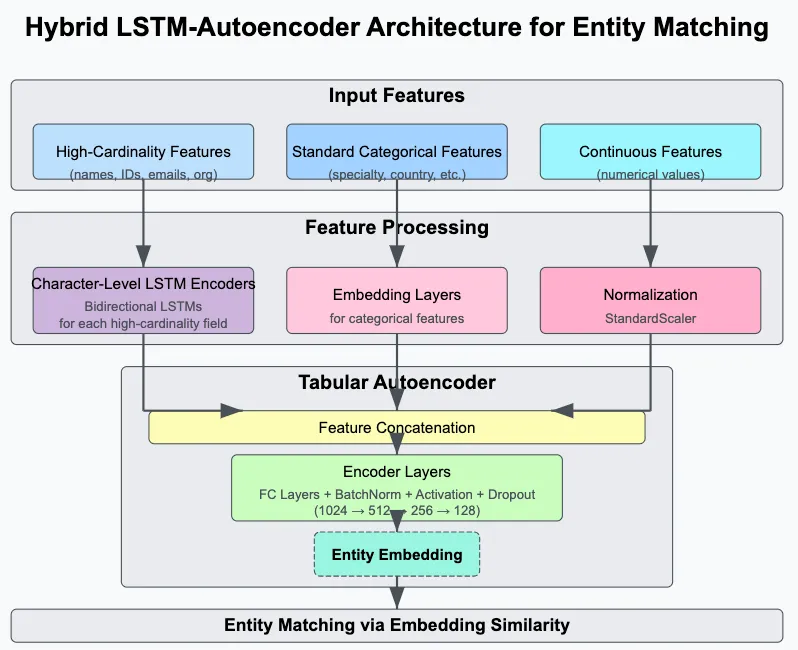 After reading related papers and exploring different ideas, here’s the model design we came up with.
After reading related papers and exploring different ideas, here’s the model design we came up with.
🔧 Feature Extractor Model
We use a separate feature extractor for high-cardinality columns such as name, email, and individual IDs. These fields can’t be directly treated as categorical or continuous variables in the main auto-encoder.
So, we built an LSTM-based encoder trained purely for reconstruction, without added noise. We then extract embeddings from the encoder’s hidden states.
➡️ This works fine in terms of minimizing reconstruction loss. But whether the embeddings capture semantically meaningful representations for downstream tasks remains uncertain.
For semantically rich fields like organization and specialty, I used Sentence Transformers instead.🔧 Main Autoencoder Model
The main model is an auto-encoder and concatenates:- All embeddings from the high-cardinality feature extractors
- The remaining categorical columns (there are no continuous features in this dataset)
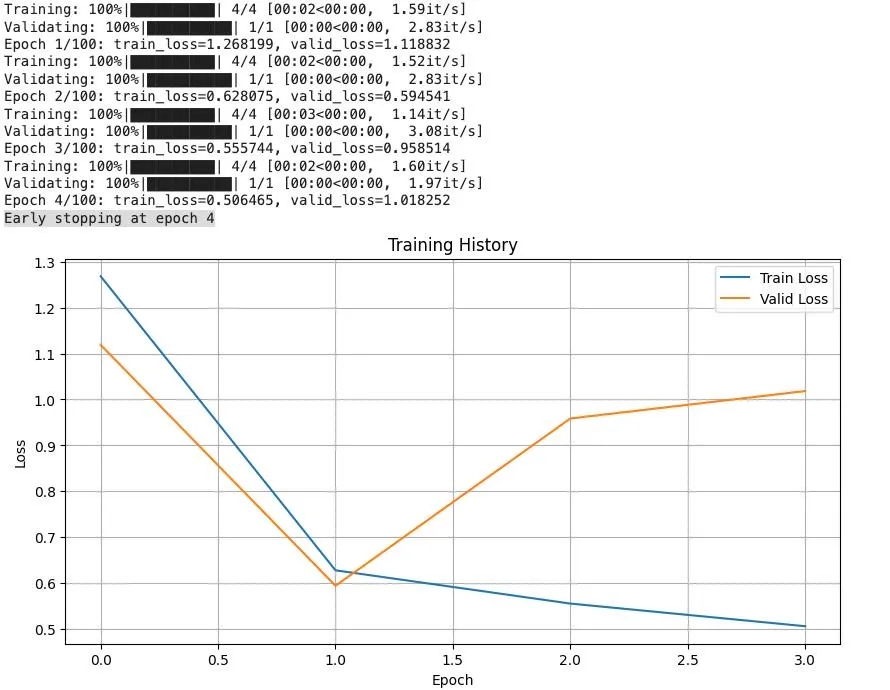
Is this model an overkill for the data we tested?
There are still ways to simplify the model. I’ll test them next and continue sharing what I learn along the way.