
Research log #3
When the Model Knows Too Much
By Lidia on Fri Jun 13 2025
In my previous log, I concluded that we might be using the wrong tool with the wrong data. The proxy task failed mainly because there wasn’t a proper column to anchor the learning but that doesn’t necessarily mean the main task is doomed. After all, it’s just a proxy task.
This brings me back to a fundamental question that I asked earlier:
How do we know if our model is working for the actual task?
How do we know if the embeddings are meaningful?
It’s hard to answer this when the model starts overfitting after the very first epoch.
🤯 Problem: Model Too Big, Data Too Small
One clear issue I noticed: the input vector was huge — over 1,100 dimensions — leading to an explosion in parameter count.
Encoder Design (Before)
input_size → 1024 → 512 → 256 → 128For input size = 1,000:
- 1st layer alone: 1,000 × 1,024 = 1,024,000 parameters
- Then: 1,024 × 512 = 524,288
- Total parameters in the encoder: ~2–3 million
With only ~4,000 rows in the dataset, that’s hundreds of parameters per row — more than enough for the model to memorize quirks and noise rather than learn generalizable patterns.
In other words, the model had enough capacity to latch onto specific patterns — even tiny, noisy ones — from individual rows. As a result, it struggled on new, unseen data because it wasn’t learning general patterns, just memorizing specific cases.
To generalize well, a model needs:- Enough data to constrain its capacity
- Simpler architecture
- Or regularization (dropout, weight decay, etc.)
Experiments: Making the Model Simpler
Here’s what I changed and tested:1. Reduce Input Vector Size
I removed SentenceTransformer (ST) embeddings (768 dims) and normalized high-cardinality columns instead.
- Original input size: 1119
- New input size: 351
This means I had to temporarily exclude two potentially valuable features. I plan to revisit these columns later with proper dimensionality reduction (e.g., PCA).
2. Shrink the Encoder
input_size → 512 → 256 → 128
3. Tune Regularization
- Dropout increased from 0.1 → 0.2 or 0.3
- Weight decay set to 0.01 or 0.02
4. Reduce Batch Size
- From 1024 → 64
This slowed down training, but led to more stable and smoother convergence.
Summary of Findings
➤ SentenceTransformer Embeddings
- 1119-dim (with ST): Early overfitting (val_loss spikes by epoch 2–3)
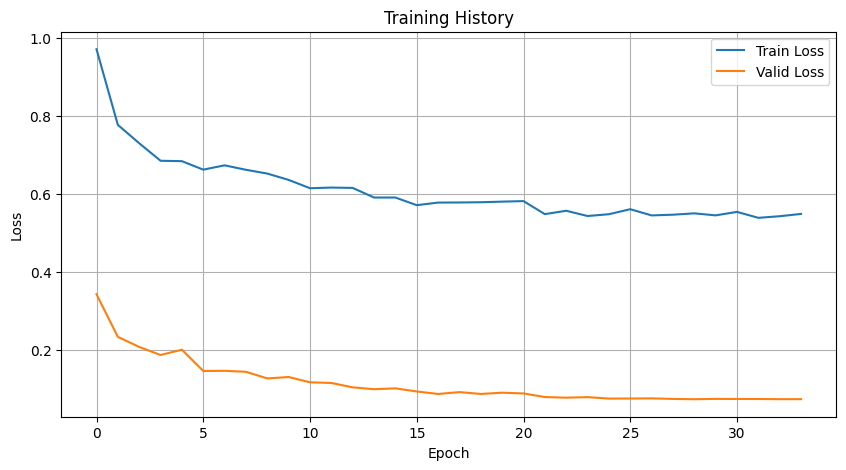
- 351-dim (no ST): More stable training, better generalization
✅ Removing ST embeddings improved learning. They may introduce too much noise or inflate model size. Consider PCA or other dimensionality reduction before reintegrating them.
➤ Encoder Size
- Shrinking the encoder delayed overfitting and improved validation loss.
✅ A smaller encoder fits the dataset’s scale more appropriately.
➤ Batch Size
- 1024: Faster, less stable
- 64: Slower but smoother convergence, better val_loss
✅ Small batches help the model converge reliably, especially with increased patience.
➤ Dropout + Weight Decay
- Best results at dropout=0.2, weight_decay=0.01~0.02
- Dropout 0.3 with high weight decay = performance drop
✅ Mild regularization works. Too much hurts.
🏆 Best Configurations

Next, I’ll explore applying PCA to ST features and — more importantly — evaluate the quality of the embeddings directly through similarity search for duplicate detection.