
Research log #4
Reconstruction ≠ Representation
By Lidia on Sun Jun 22 2025
In the last post, I shared a bit of cautious optimism: the model wasn’t overfitting immediately, and the loss was steadily decreasing. At least on paper, it looked like the autoencoder was learning.
But the core question still stands:
How do we evaluate whether the model is actually learning meaningful representations?
Cosine Similarity
To evaluate that, I started by validating the embeddings generated by the autoencoder using cosine similarity.
Unsurprisingly, the results from the first trial weren’t encouraging.
Unless the similarity score was exactly 1.00, the records were completely different—even at 0.99.
That’s a red flag.
❗️Conclusion: The Embeddings Don’t Represent
Even though the model learns to reconstruct the input, that doesn’t necessarily mean it’s learning to represent the data in a way that preserves semantic closeness or entity-level similarity.
To get a more intuitive sense of what was happening, I visualized the distribution of cosine similarities:
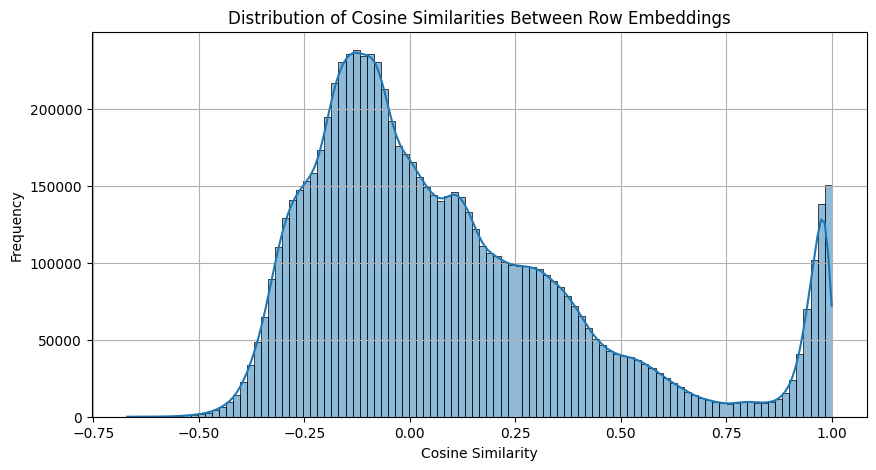
There was a suspicious spike at 1.0. This might suggest the presence of many duplicates in the dataset—but I’d already verified that anything less than 1.0 had no meaningful resemblance.
Why This Happens
Autoencoders trained purely on reconstruction loss can perform their task well—rebuilding input from compressed representations—yet still fail to learn representations that are useful for tasks like similarity search or entity resolution.
In my case, the model is optimizing for pixel-perfect reconstruction, not for keeping similar records close together in latent space.
What’s Next?
The experiment continues. Here’s what I’m exploring next:
- Fuzzy matching test cases: Compare scores against known fuzzy matches.
- Standardize missing categorical features: Use OpenRefine to clean up fields like org and specialty, and re-evaluate similarity.
- Component isolation: Evaluate helper networks independently (e.g., LSTM-autoencoder for name).
- Remove high-cardinality fields: See how the main model behaves when trained only on categorical features.
- Try new datasets: The current dataset might have structural biases (e.g., shared default or missing values). I’ll try a different dataset.