
Research log #5
Why Does Logistic Regression Work Surprisingly Well for Deduplication?
By Lidia on Mon Jul 07 2025
Logistic regression models work surprisingly well for deduplication tasks on tabular data. In fact, widely used open-source tools like Zingg rely on logistic regression for entity matching.
At first glance, logistic regression might seem too basic – it’s often one of the first models we learn. But in practice, it consistently performs well for deduplication. I wanted to understand why.
1. What is Logistic Regression?
The model is fundamentally simple:
z = w1 x1 + w2 x2 + ⋯ + wn xn + b
It captures only linear relationships between features and outputs a probability between 0 and 1, making it ideal for binary classification tasks like deduplication (match vs. non-match).
2. Why Does It Work Well for Deduplication?
Deduplication often relies on engineered features such as string similarity scores, numeric differences, or binary match indicators. These features are often linearly separable, which fits logistic regression’s assumptions well.
Other advantages include:
- Interpretability: Feature coefficients indicate which comparisons drive decisions.
- Efficiency: Training is fast, which is critical for active learning workflows.
- Clear probability outputs: Makes threshold setting straightforward
3. Comparing With More Complex Models
In my experience, more complex models like autoencoders and random forests don’t always outperform logistic regression in deduplication tasks.
For example:
- Autoencoders
They are designed to reconstruct input data well. When duplicates are almost exact copies except for minor differences (e.g. a missing field or a nickname variation), the autoencoder easily learns to reconstruct both the original and the duplicate without needing to encode those subtle differences. The reconstruction loss doesn’t pressure the model to focus on matching-related signals. - Random Forests
They tend to latch onto the most obvious single-field signals, like first name similarities, without learning deeper interaction patterns across multiple features.
While this can give high accuracy on training data, it often fails to generalize when duplicates differ in less obvious ways.
Overall, this leads to:
✅ High performance on training data,
❌ But poor generalization when duplicates deviate from the near-exact patterns the model learned.
4. The Fundamental Evaluation Problem in Deduplication
A key challenge in evaluating any deduplication solution is: You don't know what you don't know.
In other words:
- You rarely know the total number of true duplicates in the full dataset.
- Even if your model performs well on labeled pairs, it might still miss unseen match patterns.
Given this uncertainty, using a simple, interpretable, and fast model like logistic regression becomes even more attractive.
5. Learning from Self-Supervised Representation Studies
Logistic regression is also widely used as a linear probe to evaluate embedding quality in self-supervised learning:
For example, SubTab (Uçar et al., 2021) and STaB (Ehsan et al., 2022):
- Pretrain an encoder with self-supervised objectives (contrastive loss, feature masking, etc.).
- Freeze the encoder.
- Extract embeddings for labeled rows.
- Train a logistic regression model on top to assess how linearly separable the classes are.
I tried this approach myself and here is the result. In the previous log, I used cosine similarity to evaluate embeddings. While cosine similarity tests geometric closeness, logistic regression tests class separability.
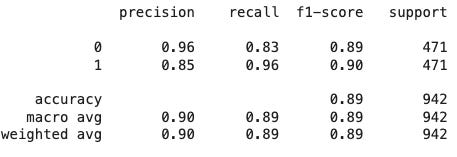
Interestingly, even when cosine similarity failed to distinguish duplicates, logistic regression still performed well – suggesting the embeddings contained useful signals not obvious geometrically.
Conclusion
One fundamental issue still remains:
➡️ High scores don’t necessarily mean my model is “smart”; they might just mean your data is “easy”.
But as I continue experimenting with more complex and messy datasets, logistic regression will remain a baseline to benchmark against and a useful tool to probe embedding quality.